Which two actions are needed to advertise OSPF routes to BGP neighbors? Choose two.
You have a problem bringing up an aggregated Ethernet interface between a spine and a leaf.

Referring to the exhibit, what is the problem?
A switch receives an Ethernet frame that contains source and destination MAC addresses that are not in the Ethernet switching table. In this scenario, which two actions does the switch perform? Choose two.
Referring to the exhibit,

how much time must pass before a neighbor is considered down?
Exhibit:
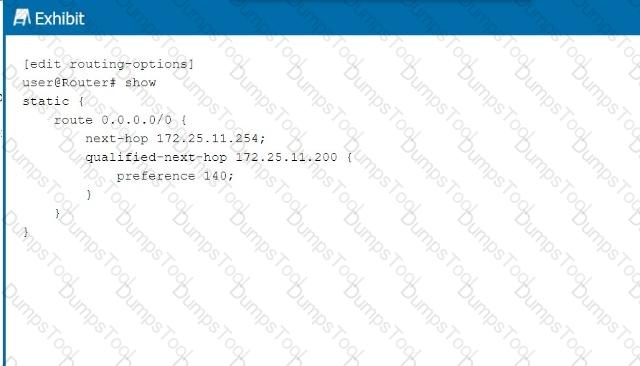
Referring to the exhibit, what is the route preference of the 172.25.11.254 next hop?
You are creating an IP fabric underlay and want to use OSPF as your routing protocol.
In this scenario, which statement is correct?
You want to enable routing between VLAN 10 and VLAN 20.

Which two configuration statements must be included in the configuration shown in the exhibit to accomplish this task? Choose two.
According to Juniper Networks, the bridge table is more commonly known as a _________.
Which statement about the qualified next-hop feature is correct when configuring a static route?
What are two available modes when using LACP with an aggregated Ethernet bundle? Choose two.
When using spine and leaf fabric architectures, what is the role of each device? (Choose two.)
You are troubleshooting BGP routing and want to verify that you are sending a default route to peer address 10.100.25.6. Which command would satisfy the requirement?

TESTED 14 Jul 2026
