Which Azure service can use the prebuilt receipt model in Azure Al Document Intelligence?
You are authoring a Language Understanding (LUIS) application to support a music festival.
You want users to be able to ask questions about scheduled shows, such as: “Which act is playing on the main stage?”
The question “Which act is playing on the main stage?” is an example of which type of element?
You need to provide content for a business chatbot that will help answer simple user queries.
What are three ways to create question and answer text by using Azure Al Language Service ' s question answering? Each correct answer presents a complete solution.
NOTE: Each correct and ask questions by selection is worth one point.
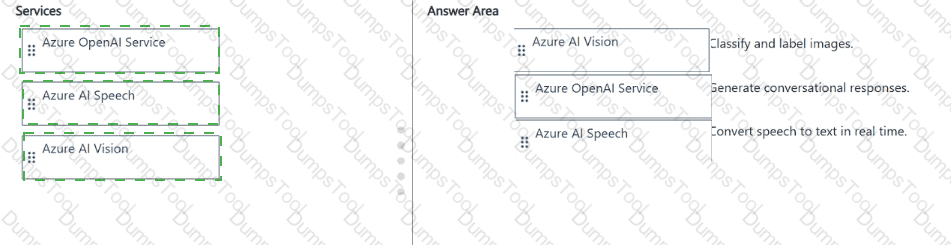
Match the Azure Cognitive Services to the appropriate Al workloads.
To answer, drag the appropriate service from the column on the left to its workload on the right. Each service may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.

For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

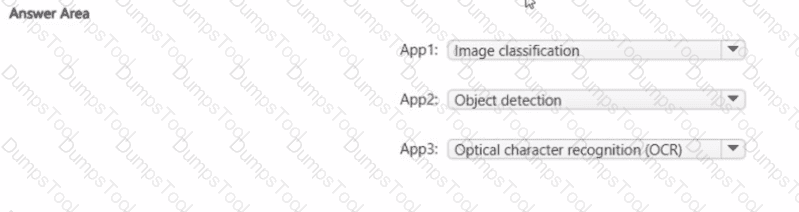
You have the following apps:
• App1: Uses a set of images of tumors to identify whether the tumors are benign or malignant and suggest a treatment
• App2: Uses images from cameras to track individual livestock as they move around a farm
• App3: Identifies brands in photographs of billboards
What does each app use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

You deploy the Azure OpenAI service to generate images.
You need to ensure that the service provides the highest level of protection against harmful content.
What should you do?
You need to create a training dataset and validation dataset from an existing dataset.
Which module in the Azure Machine Learning designer should you use?
You plan to create an Al application by using Azure Al Foundry. The solution will be deployed to dedicated virtual machines. Which deployment option should you use?
You need to create a clustering model and evaluate the model by using Azure Machine Learning designer. What should you do?
Which Azure service can use the prebuilt receipt model in Azure Document Intelligence in Foundry Tools?
You have a bot that identifies the brand names of products in images of supermarket shelves.
Which service does the bot use?
You need to identify street names based on street signs in photographs.
Which type of computer vision should you use?
To complete the sentence, select the appropriate option in the answer area.

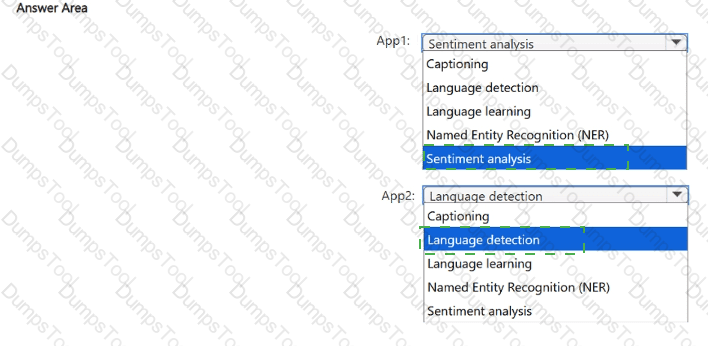
You have the following apps:
• App1: Understands the public perception of a brand or topic
• App2: Applies profanity filters to speech-to-text
What does each app use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Which Computer Vision feature can you use to generate automatic captions for digital photographs?
To complete the sentence, select the appropriate option in the answer area.

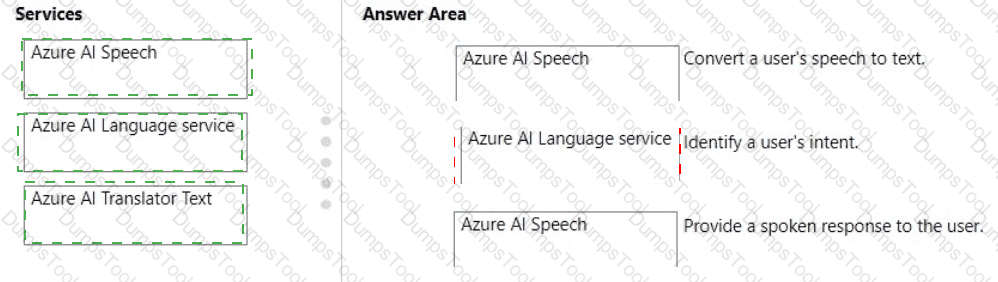
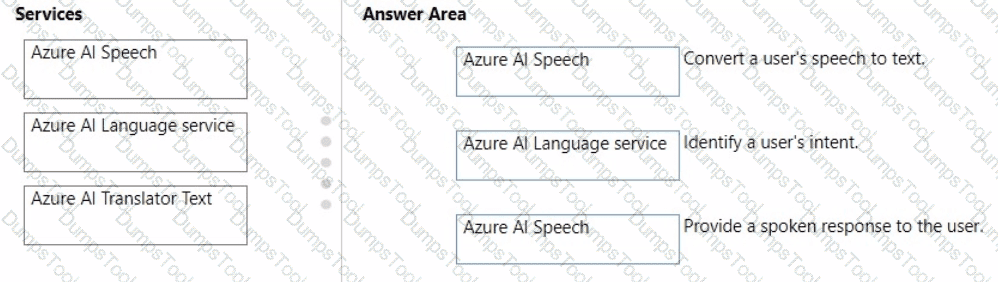
You plan to use Azure Cognitive Services to develop a voice controlled personal assistant app.
Match the Azure Cognitive Services to the appropriate tasks.
To answer, drag the appropriate service from the column on the left to its description on the right Each service may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.

Which Azure Machine Learning capability should you use to quickly build and deploy a predictive model without extensive coding?
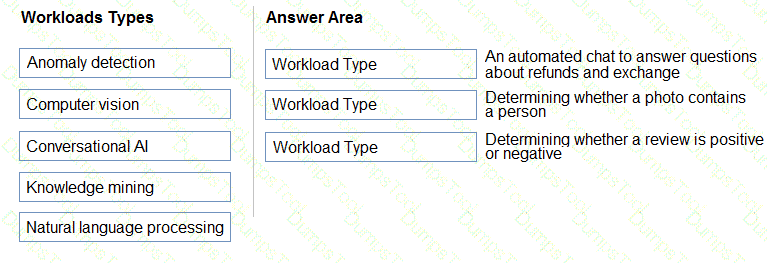
Match the types of AI workloads to the appropriate scenarios.
To answer, drag the appropriate workload type from the column on the left to its scenario on the right. Each workload type may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.
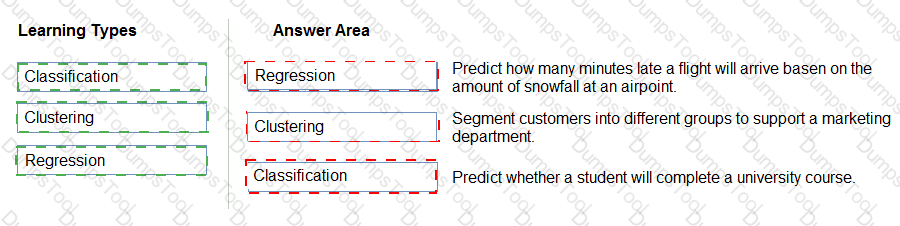
Match the types of machine learning to the appropriate scenarios.
To answer, drag the appropriate machine learning type from the column on the left to its scenario on the right. Each machine learning type may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.

You are developing a Chabot solution in Azure.
Which service should you use to determine a user’s intent?
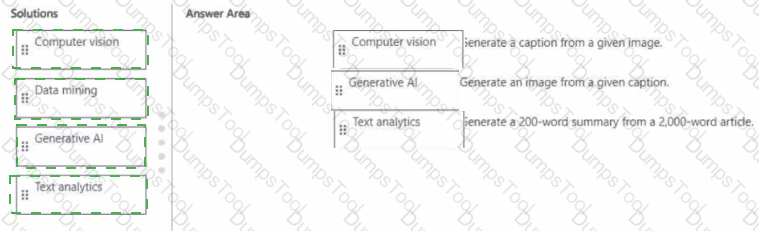
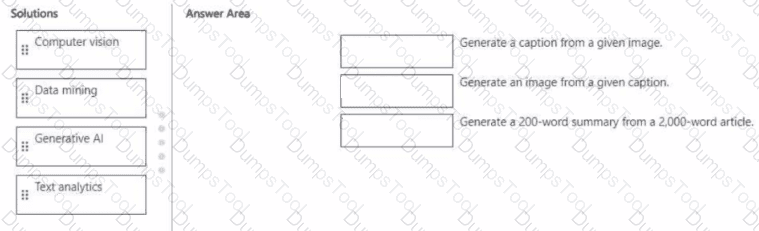
Match the Al solution to the appropriate task.
To answer, drag the appropriate solution from the column on the left to its task on the right. Each solution may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.
Which two scenarios are examples of a natural language processing workload? Each correct answer presents a complete solution.
NOTE; Each correct selection is worth one point.
To complete the sentence, select the appropriate option in the answer area.

You need to predict the income range of a given customer by using the following dataset.
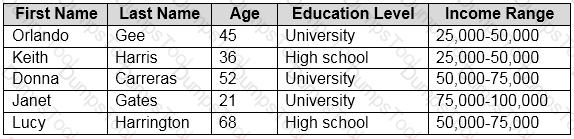
Which two fields should you use as features? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
You need to build an app that will identify celebrities in images.
Which service should you use?
What are three Microsoft guiding principles for responsible AI? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
What are two types of generative Al models? Each correct answer presents a complete solution. NOTE: Each correct answer is worth one point.
You need to count the number of animals in a photograph. Which type of computer vision should you use?
You have a dataset that contains information about taxi journeys that occurred during a given period.
You need to train a model to predict the fare of a taxi journey.
What should you use as a feature?
You have insurance claim reports that are stored as text.
You need to extract key terms from the reports to generate summaries.
Which type of Al workload should you use?
Match the principles of responsible AI to appropriate requirements.
To answer, drag the appropriate principles from the column on the left to its requirement on the right. Each principle may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

You need to create a customer support solution to help customers access information. The solution must support email, phone, and live chat channels. Which type of Al solution should you use?
You have a webchat bot that provides responses from a QnA Maker knowledge base.
You need to ensure that the bot uses user feedback to improve the relevance of the responses over time.
What should you use?
You need to identify groups of rows with similar numeric values in a dataset. Which type of machine learning should you use?
Which term is used to describe uploading your own data to customize an Azure OpenAI model?
Which two actions can you perform by using the Azure OpenAI DALL-E model? Each correct answer presents a complete solution.
NOTE: Each correct answer is worth one point.
You need to identify harmful content in a generative Al solution that uses Azure OpenAI Service.
What should you use?
What are two metrics that you can use to evaluate a regression model? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
Which Azure Cognitive Services service can be used to identify documents that contain sensitive information?
What are three stages in a transformer model? Each correct answer presents a complete solution.
NOTE: Each correct answer is worth one point.
For which two workloads can you use computer vision? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
Which type of machine learning should you use to predict the number of gift cards that will be sold next month?
You need to develop a web-based AI solution for a customer support system. Users must be able to interact with a web app that will guide them to the best resource or answer.
Which service should you integrate with the web app to meet the goal?
You need to implement a pre-built solution that will identify well-known brands in digital photographs. Which Azure Al sen/tee should you use?
To complete the sentence, select the appropriate option in the answer area.
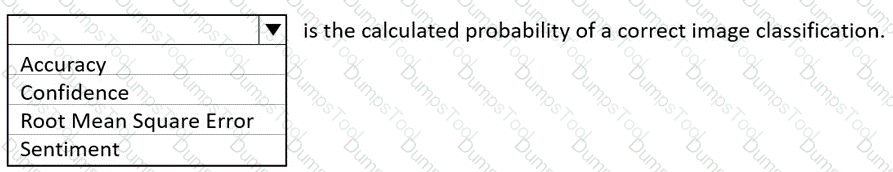
Match the Azure OpenAI large language model (LLM) process to the appropriate task.
To answer, drag the appropriate process from the column on the left to its task on the right. Each process may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.

You send an image to a Computer Vision API and receive back the annotated image shown in the exhibit.

Which type of computer vision was used?
You are building a knowledge base by using QnA Maker. Which file format can you use to populate the knowledge base?
When you design an AI system to assess whether loans should be approved, the factors used to make the decision should be explainable.
This is an example of which Microsoft guiding principle for responsible AI?
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point

You have an Al-based loan approval system.
During testing, you discover that the system has a gender bias.
Which responsible Al principle does this violate?
You are building an AI-based app.
You need to ensure that the app uses the principles for responsible AI.
Which two principles should you follow? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

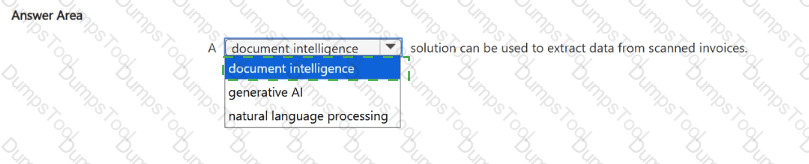
What can be used to analyze scanned invoices and extract data, such as billing addresses and the total amount due?
You are building a Language Understanding model for an e-commerce business.
You need to ensure that the model detects when utterances are outside the intended scope of the model.
What should you do?
When training a model, why should you randomly split the rows into separate subsets?
Which AI service can you use to interpret the meaning of a user input such as “Call me back later?”
You have an Azure subscription that uses Azure OpenAI.
You need to create an original image of a rural scene to use on a website.
What should you do?
You have an Azure Machine Learning model that predicts product quality. The model has a training dataset that contains 50,000 records. A sample of the data is shown in the following table.

For each of the following Statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
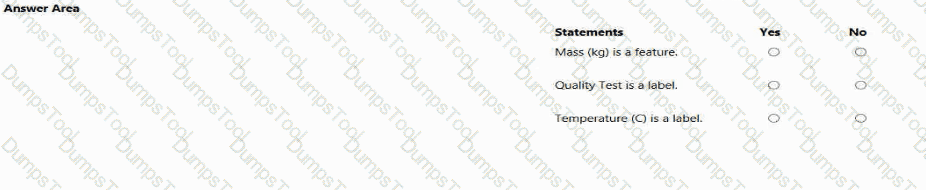
You need to predict the sea level in meters for the next 10 years.
Which type of machine learning should you use?
You are developing a conversational AI solution that will communicate with users through multiple channels including email, Microsoft Teams, and webchat.
Which service should you use?
You need to analyze images of vehicles on a highway and measure the distance between the vehicles. Which type of computer vision model should you use?
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

A company employs a team of customer service agents to provide telephone and email support to customers.
The company develops a webchat bot to provide automated answers to common customer queries.
Which business benefit should the company expect as a result of creating the webchat bot solution?
You need to predict the animal population of an area.
Which Azure Machine Learning type should you use?
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

A smart device that responds to the question. " What is the stock price of Contoso, Ltd.? " is an example of which Al workload?
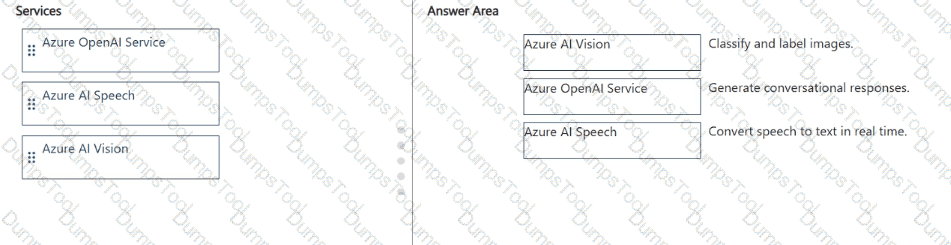
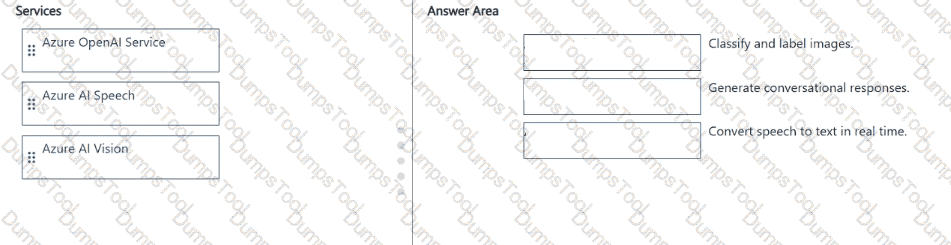
Match the Azure Al service to the appropriate generative Al capability.
To answer, drag the appropriate service from the column on the left to its capability on the right. Each service may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.
You have an Al solution that provides users with the ability to control smart devices by using verbal commands.
Which two types of natural language processing (NLP) workloads does the solution use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You need to determine the location of cars in an image so that you can estimate the distance between the cars.
Which type of computer vision should you use?
To complete the sentence, select the appropriate option in the answer area.

You need to reduce the load on telephone operators by implementing a chatbot to answer simple questions with predefined answers.
Which two AI service should you use to achieve the goal? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
Which two languages can you use to write custom code for Azure Machine Learning designer? Each correct answer presents a complete solution.
NOTE; Each correct selection is worth one point.
What are two tasks that can be performed by using the Computer Vision service? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
You are processing photos of runners in a race.
You need to read the numbers on the runners ' shirts to identify the runners in the photos. Which type of computer vision should you use?

TESTED 17 Jul 2026