Suppose A, B , and C are events. The probability of A given B , relative to P(|C), is the same as the probability of A given B and C (relative to P ). That is,
Regularization is a very important technique in machine learning to prevent overfitting. Mathematically speaking, it adds a regularization term in order to prevent the coefficients to fit so perfectly to overfit. The difference between the L1 and L2 is...
Suppose a man told you he had a nice conversation with someone on the train. Not knowing anything about this conversation, the probability that he was speaking to a woman is 50% (assuming the train had an equal number of men and women and the speaker was as likely to strike up a conversation with a man as with a woman). Now suppose he also told you that his conversational partner had long hair. It is now more
likely he was speaking to a woman, since women are more likely to have long hair than men.____________
can be used to calculate the probability that the person was a woman.
Google Adwords studies the number of men, and women, clicking the advertisement on search
engine during the midnight for an hour each day.
Google find that the number of men that click can be modeled as a random variable with distribution
Poisson(X), and likewise the number of women that click as Poisson(Y).
What is likely to be the best model of the total number of advertisement clicks during the midnight for an hour ?
A website is opened 3 times by a user. What is the probability of he clicks 2 times the advertisement, is best calculated by
Consider flipping a coin for which the probability of heads is p, where p is unknown, and our goa is to estimate p. The obvious approach is to count how many times the coin came up heads and divide by the total number of coin flips. If we flip the coin 1000 times and it comes up heads 367 times, it is very reasonable to estimate p as approximately 0.367. However, suppose we flip the coin only twice and we get heads both times. Is it reasonable to estimate p as 1.0? Intuitively, given that we only flipped the coin twice, it seems a bit
rash to conclude that the coin will always come up heads, and____________is a way of avoiding such rash
conclusions.
Let's say you have two cases as below for the movie ratings
1. You recommend to a user a movie with four stars and he really doesn't like it and he'd rate it two stars
2. You recommend a movie with three stars but the user loves it (he'd rate it five stars). So which statement correctly applies?

TESTED 01 Jul 2025
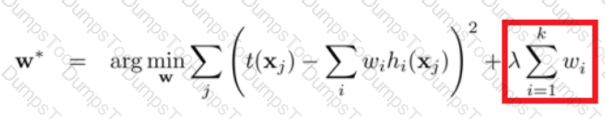 A picture containing text
Description automatically generated
A picture containing text
Description automatically generated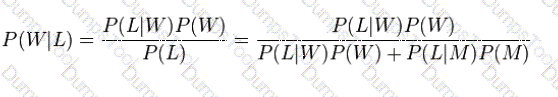 Text
Description automatically generated with low confidence
Text
Description automatically generated with low confidence A picture containing table
Description automatically generated
A picture containing table
Description automatically generated