Your cluster has the following characteristics:
Which describes the file read process when a client application connects into the cluster and requests a 50MB file?
You observed that the number of spilled records from Map tasks far exceeds the number of map output records. Your child heap size is 1GB and your io.sort.mb value is set to 1000MB. How would you tune your io.sort.mb value to achieve maximum memory to disk I/O ratio?
Cluster Summary:
45 files and directories, 12 blocks = 57 total. Heap size is 15.31 MB/193.38MB(7%)
Refer to the above screenshot.
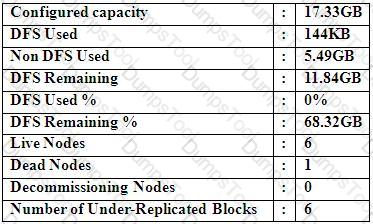
You configure a Hadoop cluster with seven DataNodes and on of your monitoring UIs displays the details shown in the exhibit.
What does the this tell you?
You are configuring a server running HDFS, MapReduce version 2 (MRv2) on YARN running Linux. How must you format underlying file system of each DataNode?

TESTED 18 Jul 2026