What DataWeave expression transforms the example XML input to the CSV output?
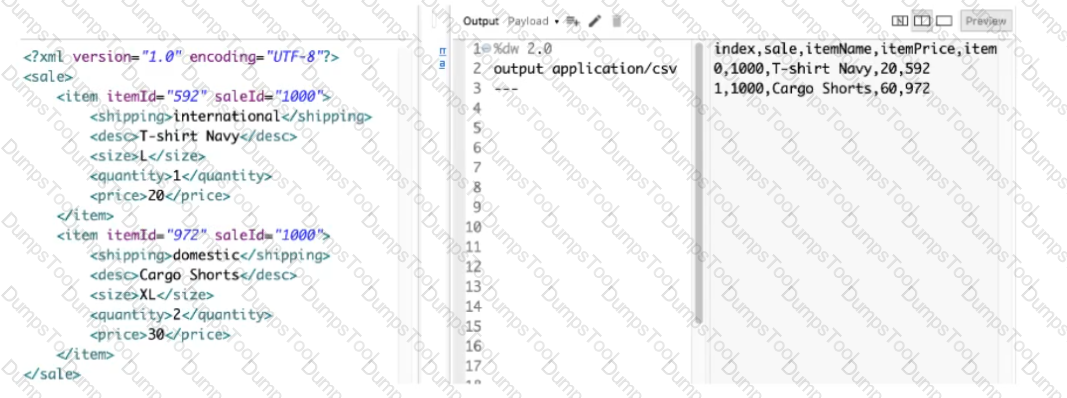
A)
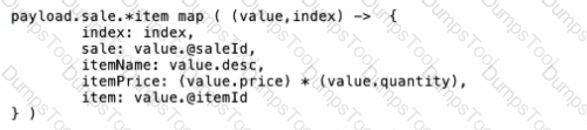
B)

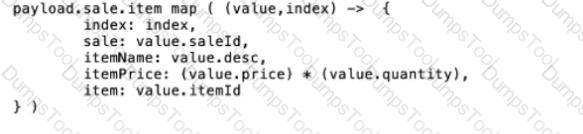
C)

D)
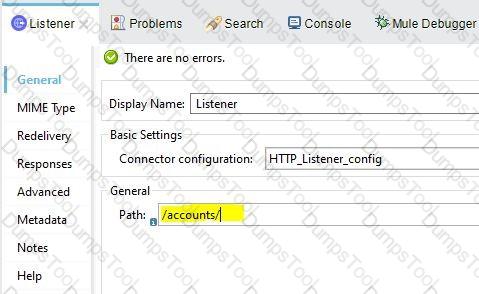
What path setting is required for an HTTP Listener endpoint to route all requests to an APIkit router?
Refer to the exhibits.
Larger image
Larger image
Larger image
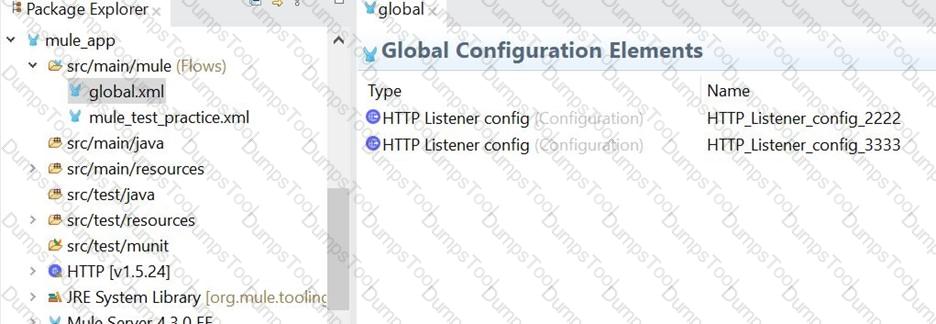
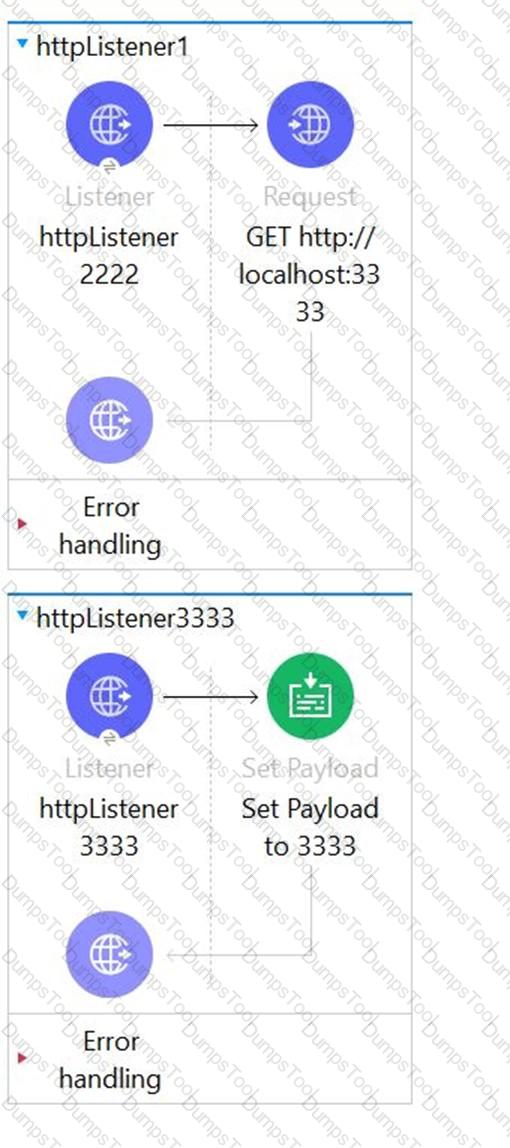
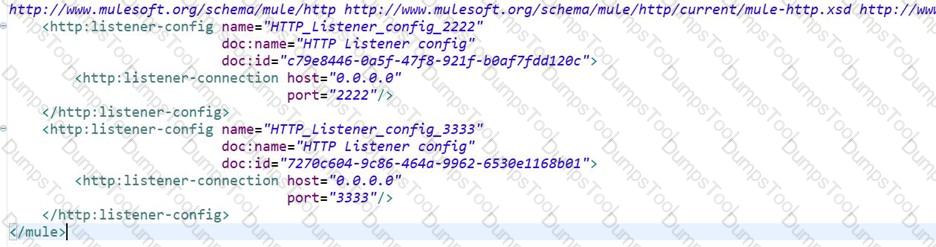
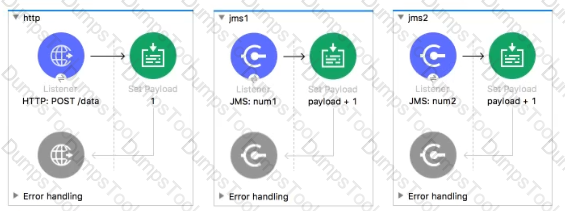
The Mule application configures and uses two HTTP Listener global configuration elements.
Mule application is run in Anypoint Studio.
If the mule application starts correctly, what URI and port numbers can receive web client requests? If the mule applications fails to start , what is the reason for the failure?
A Utility.dwl file is located in a Mule project at src/main/resources/modules. The Utility.dwl hie defines a function named pascalize that reformats strings to pascal case.
What is the correct DataWeave to call the pascalize function in a Transform Message component?
A)

B)

C)

D)

According to MuleSoft, what is the Center for Enablement’s role in the new IT operating model?
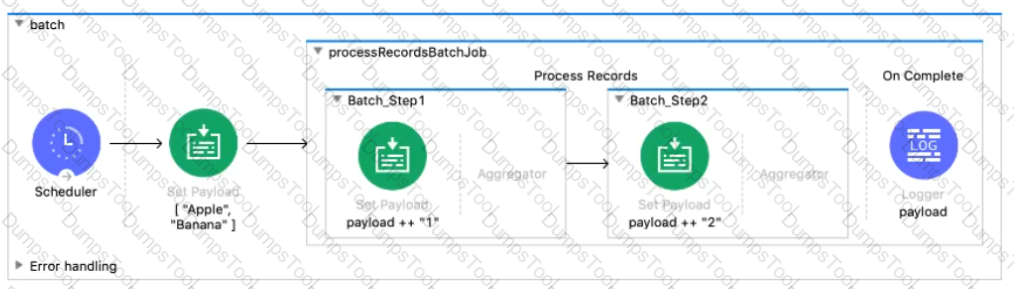
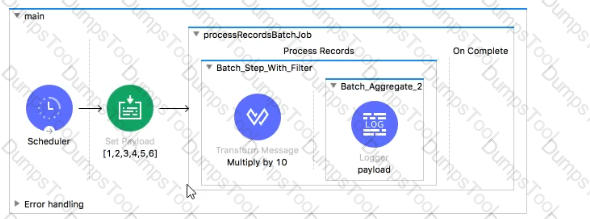
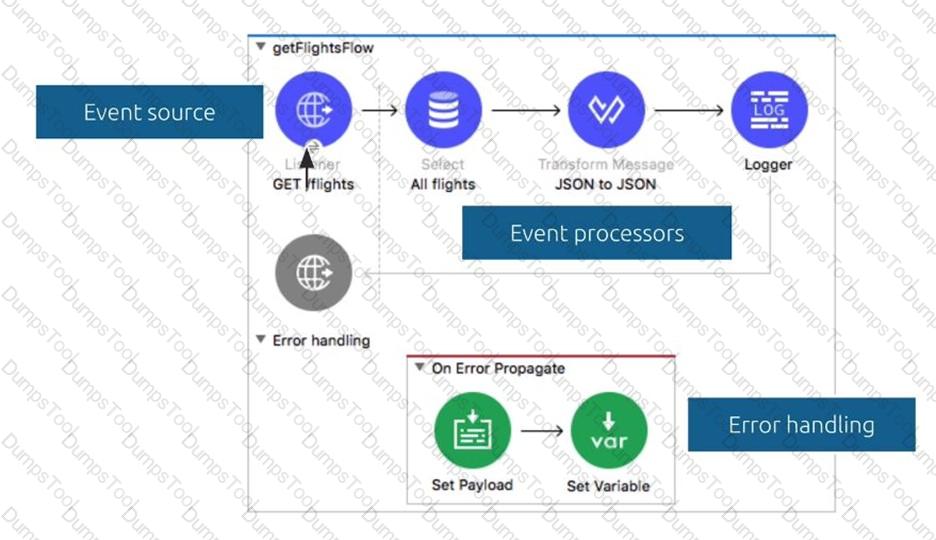
Refer to the exhibit. The input array of strings is passed to the batch job, which does NOT do any filtering or aggregating. What payload is logged by the Logger component?
Why would a Mule application use the ${http.port} property placeholder for its HTTP Listener port when it is deployed to CloudHub?
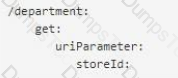
A shopping API contains a method to look up store details by department
To get information for a particular store, web clients will submit requests with a query parameter named department and a URI parameter named storeld.
What is a valid RAML snippet that supports requests from web clients to get data for a specific storeld and department name?
A)
B)
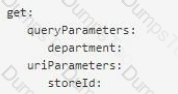
C)
D)

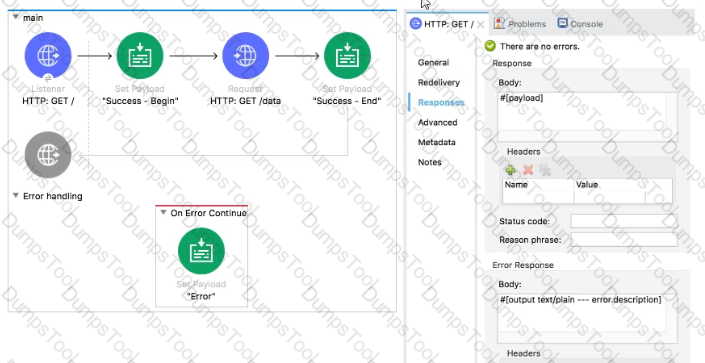
Refer to the exhibits. The main flow contains an HTTP Request operation configured to call the child flow's HTTP Listener.
A web client sends a GET request to the HTTP Listener with the sty query parameter set to 30.
After the HTTP Request operation completes, what parts of the Mule event at the main flow's Logger component are the same as the Mule event that was input to the HTTP Request operation?

Refer to the exhibit. APIkit is used to generate flow components for the RAML specification.
How many apikit:router XML elements are generated to handle requests to every endpoint defined in the RAML specification?
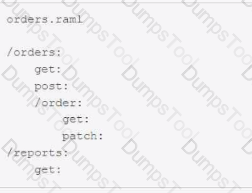
Refer to the exhibit.

What DataWeave expression transforms the conductorlds array to the XML output?
A)

B)

C)

D)

What payload is returned by a Database SELECT operation that does not match any rows in the database?
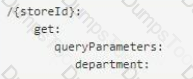
A shopping API contains a method to look up store details by department.
To get the information for a particular store, web clients will submit requests with a query parameter named department and uri parameter named storeId
What is valid RAML snippet that supports requests from a web client to get a data for a specific storeId and department name?
According to Semantic Versioning, which version would you change for incompatible API changes?
How does APIkit determine the number of flows to generate from a RAML specification?
Refer to the exhibits.
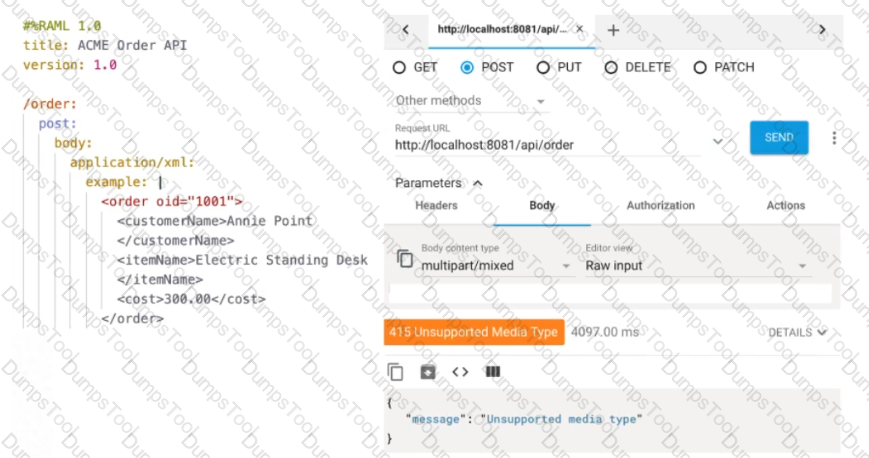
The web client sends a POST request to the ACME Order API with an XML payload. An error is returned.
What should be changed in the request so that a success response code is returned to the web client?
Refer to exhibits.
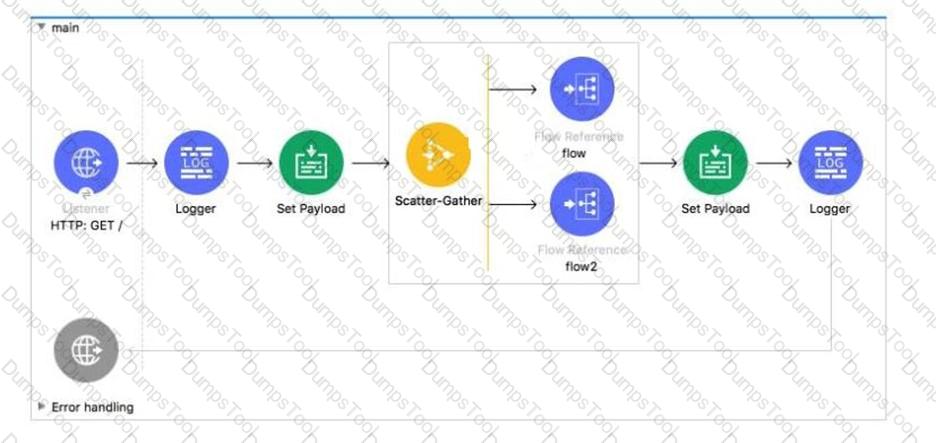
In the execution of the Scatter-Gather , the flow route completes after 10 seconds and the flow2 route completes in 40 seconds. How many seconds does it take for the Scatter-Gather to complete?
What is the correct Syntax to add a customer ID as a URI parameter in the HTTP listener's path attribute?
A Mule application contains an ActiveMQ JMS dependency. The Mule application was developed in Anypoint Studio and runs successfully in Anypoint Studio.
The Mule application must now be exported from Anypoint Studio and shared with another developer.
What export options create the smallest JAR file that can be imported into the other developer's Anypoint Studio and run successfully?

A Mule project contains a DataWeave module like WebStore.dwl that defines a function named loginUser. The module file is located in the project's src/main/resources/libs/etl folder.
What is correct DataWeave code to import all of the WebStore.dwl file's functions and then call the loginUser function for the login "Todd.Pal@mulesoft.com"?
Refer to the exhibit.
How should the WHERE clause be changed to set the city and state values from the configured input parameters?

A)

B)

C)
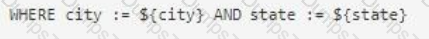
D)
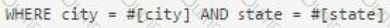
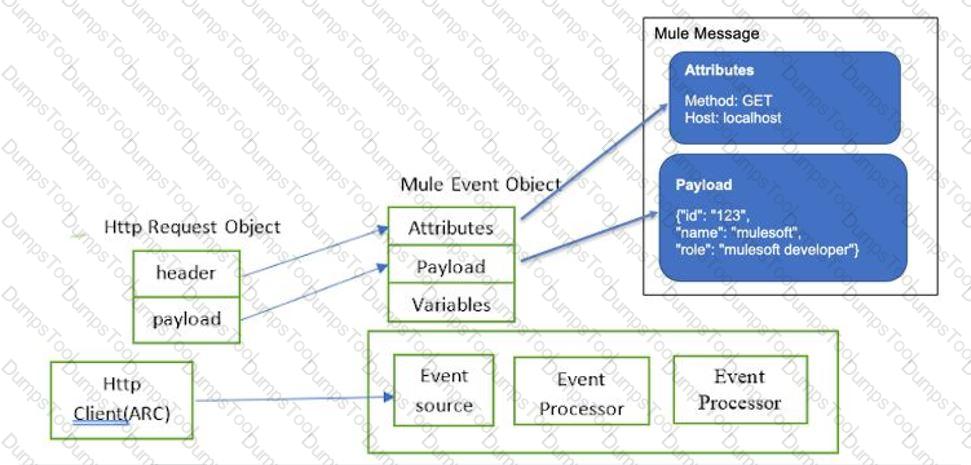
Refer to the exhibits. The main flow contains an HTTP Request in the middle of the flow. The HTTP Listeners and HTTP Request use default configurations.
A web client submits a request to the main flow's HTTP Listener that includes query parameters for the pedigree of the piano.
What values are accessible to the Logger component at the end of the main flow?
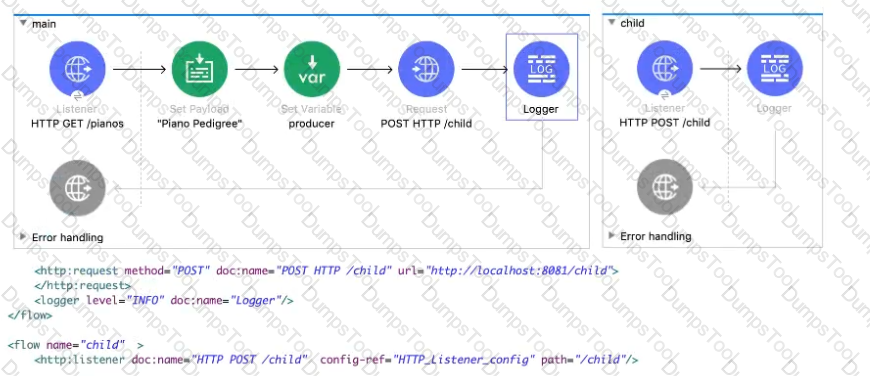
Where are values of query parameters stored in the Mule event by the HTTP Listener?
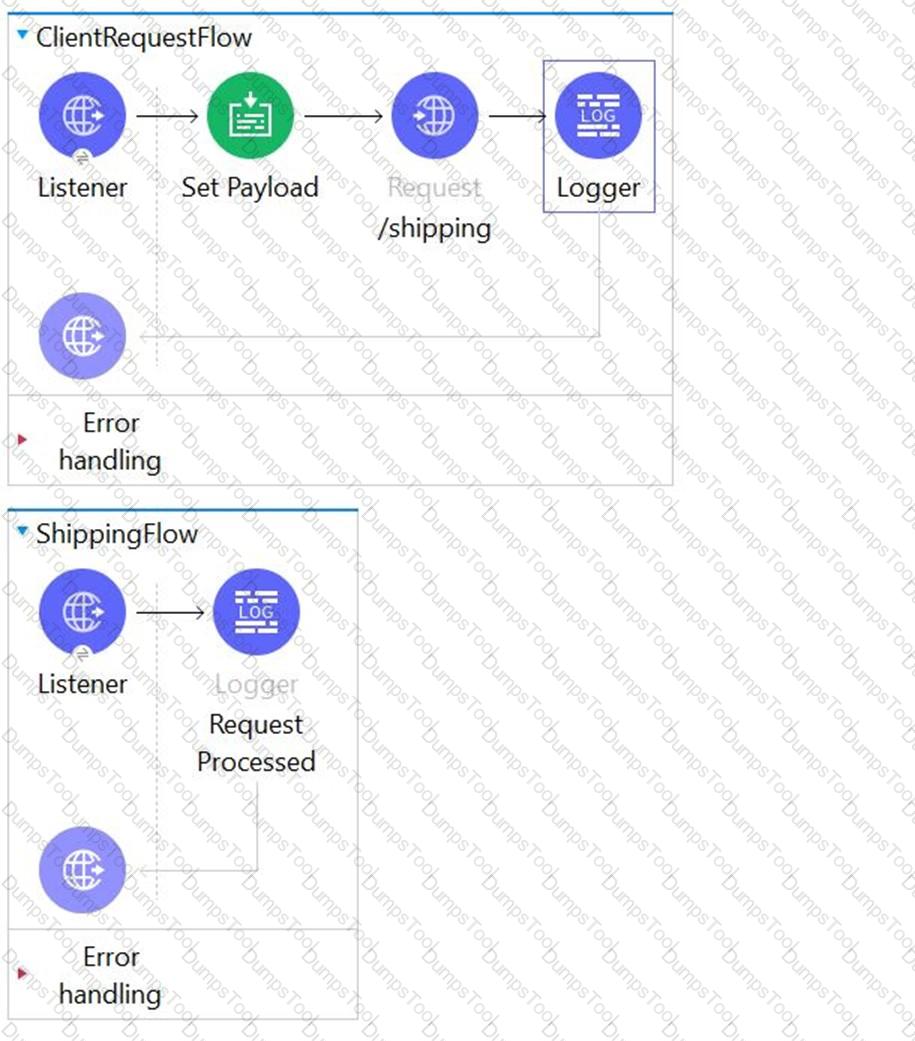
Refer to the exhibits. Client sends the request to ClientRequestFlow which calls ShippingFlow using HTTP Request activity.
During E2E testing it is found that that HTTP:METHOD_NOT_ALLOWED error is thrown whenever client sends request to this flow.
What attribute you would change in ClientRequestFlow to make this implementation work successfully?

Refer to the exhibit. The Batch Job processes, filters and aggregates records, What is the expected output from the Logger component?

Refer to the exhibit.
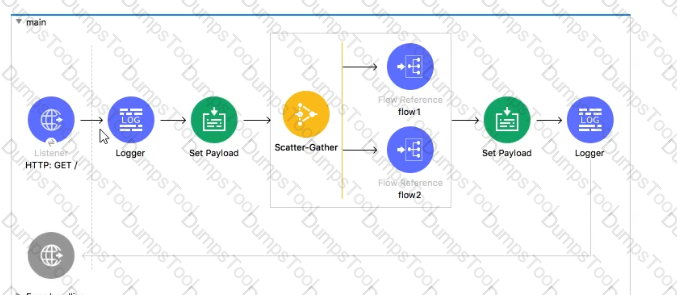
In the execution of the Scatter_Gather, the flow1 route completes after 10 seconds and the flow2 route completes after 20 seconds.
How many seconds does it take for the Scatter_Gather to complete?
Refer to the exhibits.
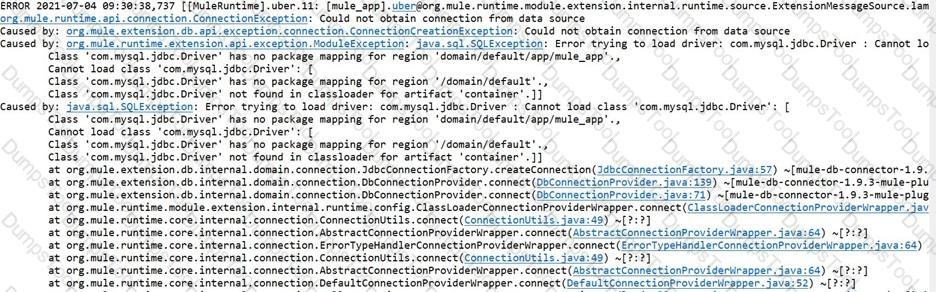
As a mulesoft developer, what you would change in Database connector configuration to resolve this error?
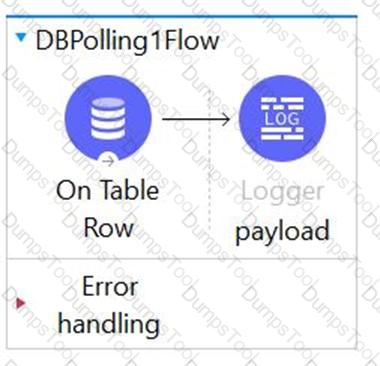
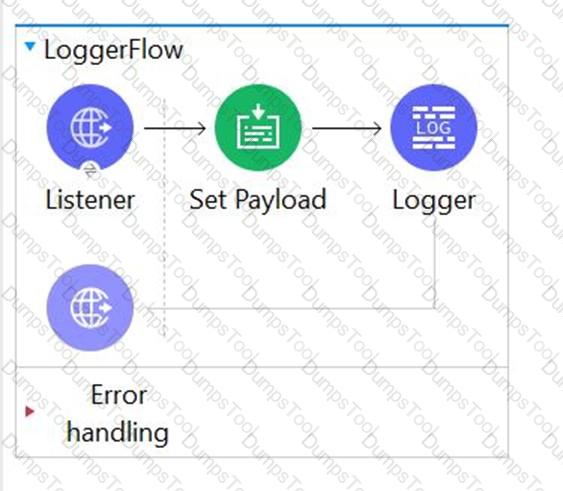
Refer to the exhibit.
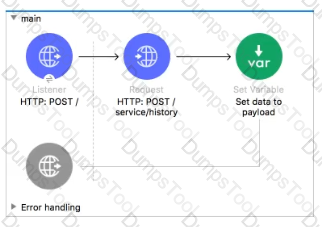
What can be added to the flow to persist data across different flow executions?
By default, what happens to a file after it is read using an FTP connector Read operation?
Refer to the exhibits.
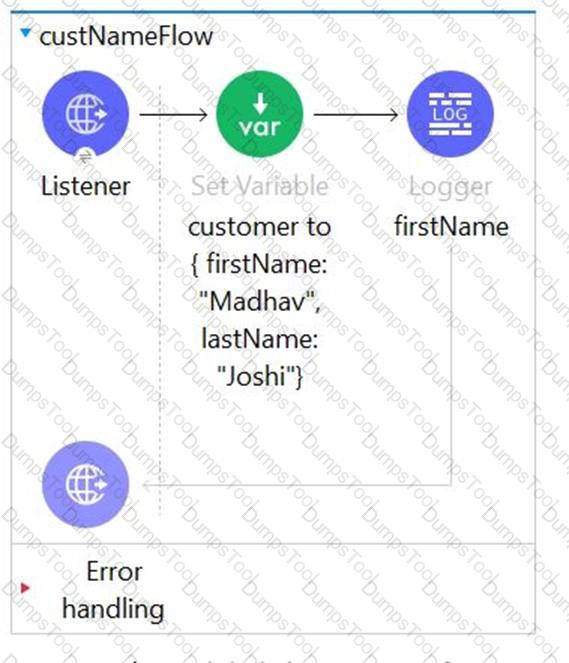

Set paylaod transformer is set the firstName and lastName of the customer as shown in below images.
What is the correct Dataweave expression which can be added in message attribute of a Logger activity to access firstName (which in this case is Madhav) from the incoming event?
Refer to the exhibits.

The Mule Application is being debugged in Anypoint Studio and stops at breakpoint. What is the value of payload displayed in debugger at this breakpoint?
Refer to the exhibits.
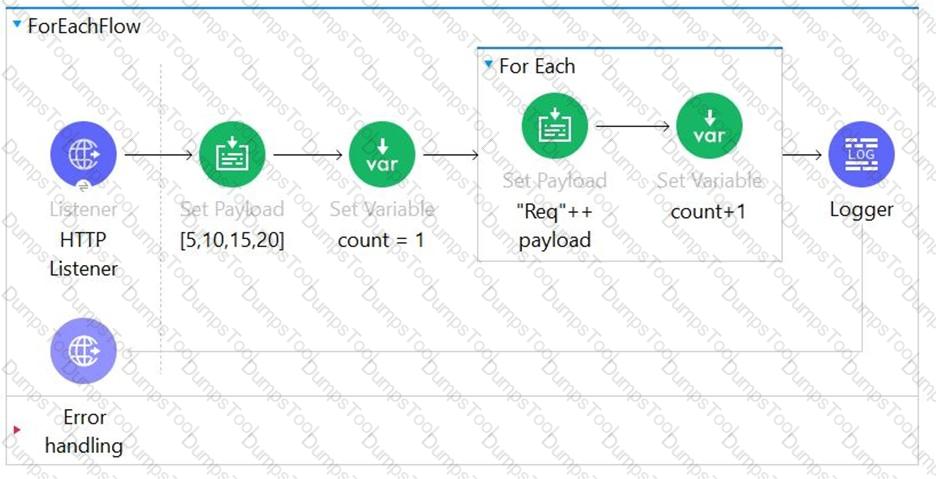
What payload and variable are logged at the end of the main flow?

Refer to the exhibits.

What is written to the records.csv file when the flow executes?
Refer to the exhibits.
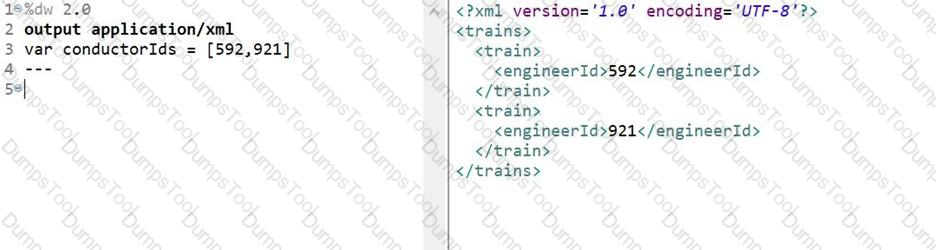
What DataWeave expression transforms the conductorIds array to the XML output?
Refer to the exhibit.
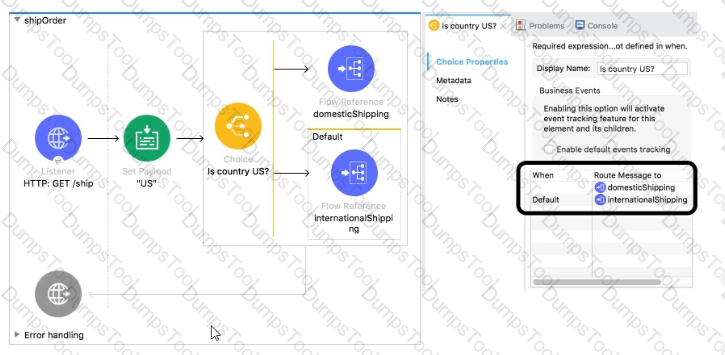
What is a valid expression for the Choice router’s when expression to route events to the documenticShipping flow?
Refer to the exhibits.
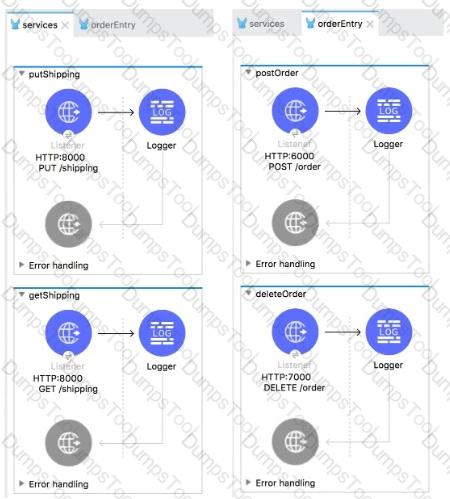
The two Mule configuration files belong to the same Mule project. Each HTTP Listener is configured with the same host string and the port number, path, and operation values are shown in the display names.
What is the minimum number of global elements that must be defined to support all these HTTP Listeners?
Refer to the exhibits.
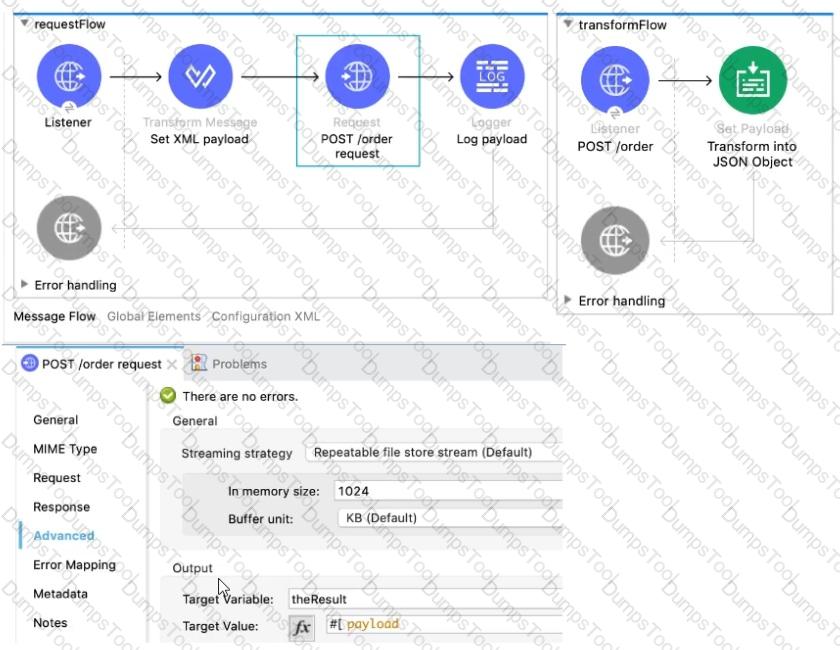
In the requestFlow an HTTP Request operation is configured to send an HTTP request with an XML payload. The request is sent to the HTTP Listener in the transform Flow.
That flow transforms the incoming payload into JSON format and returns the response to the HTTP request. The response of the request is stored in a target variable named the Result.
What is the payload at the Logger component after the HTTP Request?
What is the trait name you would use for specifying client credentials in RAML?
Refer to the exhibits.
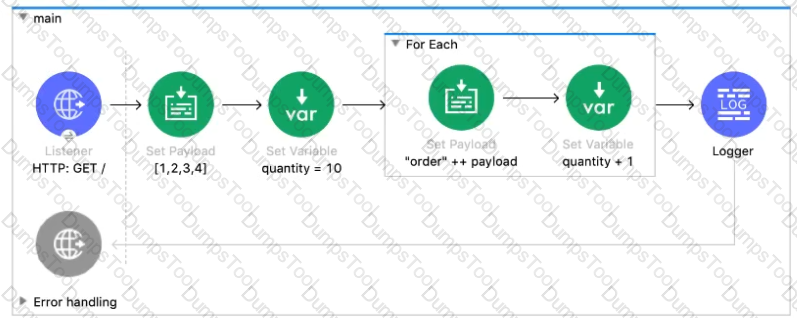

What payload and quantity are logged at the end of the main flow?
Refer to the exhibit.
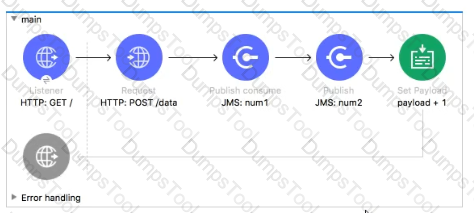

What payload is returned from a request to http//localhost.8081/
Refer to the exhibits, what payload is returned from a request to http://localhost;8081/?
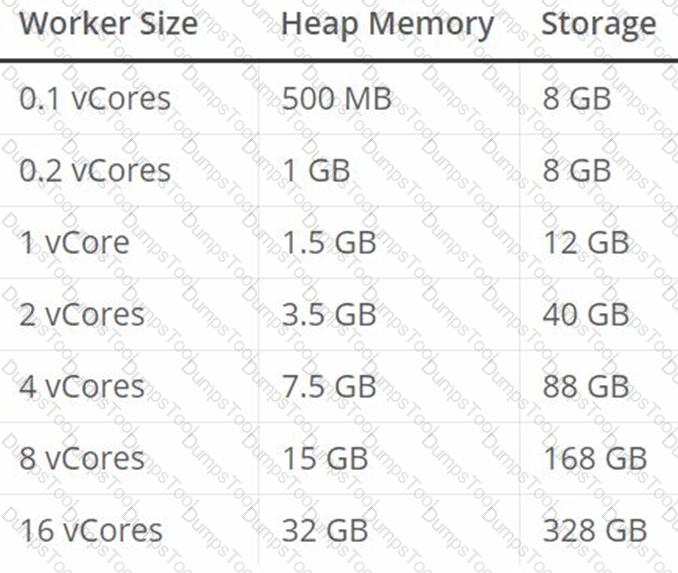
What is the minimum Cloudhub worker size that can be specified while deploying mule application?
What MuleSoft API-led connectivity layer is intended to expose part of a backend database without business logic?
An HTTP Request operation sends an HTTP request with a non-empty JSON object payload to an external HTTP endpoint. The response from the external HTTP endpoint returns an XML body. The result is stored in a target named the Result.
What is the payload at the event processor after the HTTP Request?
An API has been created in Design Center. What is the next step to make the API discoverable?
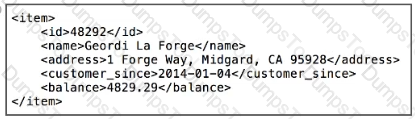
Refer to the payload.

The Set payload transformer sets the payload to an object. The logger component's message attribute is configured with the string "Result #["INFO"++ payload]"
What is the output of logger when this flow executes?
An API instance of type API endpoint with API proxy is created in API manager using an API specification from Anypoint Exchange. The API instance is also configured with an API proxy that is deployed and running in CloudHub.
An SLA- based policy is enabled in API manager for this API instance.
Where can an external API consumer obtain a valid client ID and client secret to successfully send requests to the API proxy?
Refer to the exhibit.

How many private flows does APIKIT generate from the RAML specification?
A Batch Job scope has five batch steps. An event processor throws an error in the second batch step because the input data is incomplete. What is the default behavior of the batch job after the error is thrown?
Refer to the exhibits.

A web client submits a request to the HTTP Listener and the HTTP Request throws an error.
What payload and status code are returned to the web client?
Refer to the exhibits. A web client submits a request to the HTTP Listener and the HTTP Request throws an error.
What payload and status code are returned to the web client?
Refer to the exhibits. A company has defined this Book data type and Book example to be used in APIs. What is valid RAML for an API that uses this Book data type and Book example?

A)

B)

C)

D)

What is the default port used by Mule application debugger configuration in Anypoint Studio?
Refer to the exhibit.

What data is expected by the POST /accounts endpoint?
A)

B)
C)
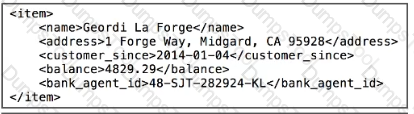
D)

Refer to the exhibits. A database Address table contains a ZIPCODE column and an increasing ID column. The Address table currently contains tour (4) records. The On Table Row Database listener is configured with its watermark set to the Address table's ZIPCODE column and then the Mule application is run in Anypoint Studio tor the first time, and the On Table Row Database listener polls the Address table.
Anew row is added to the database with 1D=5 and ZIPCODE-90006, and then the On Table Row Database listener polls the database again.
Alter the next execution of the On Table Row Database listener polling, what database rows have been processed by the Mule flow since the Mule application was started?


TESTED 02 Apr 2026
 Diagram
Description automatically generated
Diagram
Description automatically generated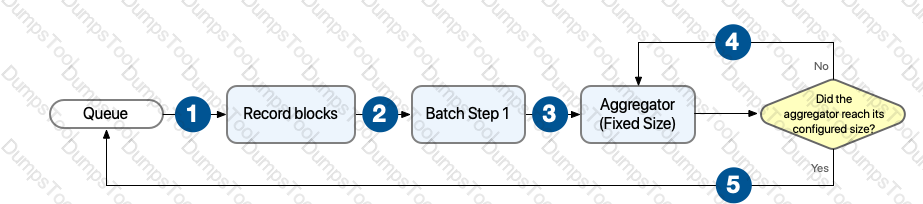 Diagram
Description automatically generated
Diagram
Description automatically generated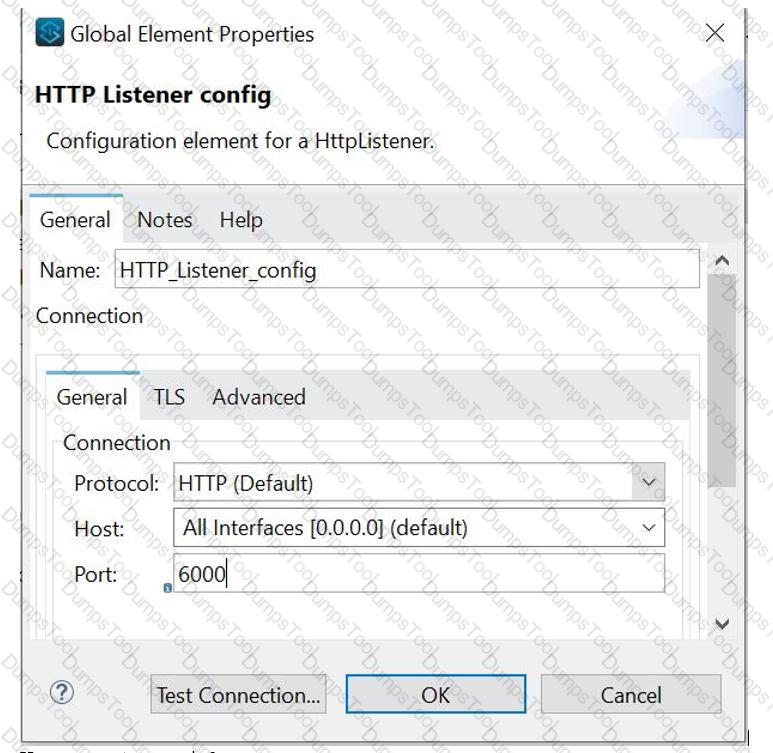 Graphical user interface, application
Description automatically generated
Graphical user interface, application
Description automatically generated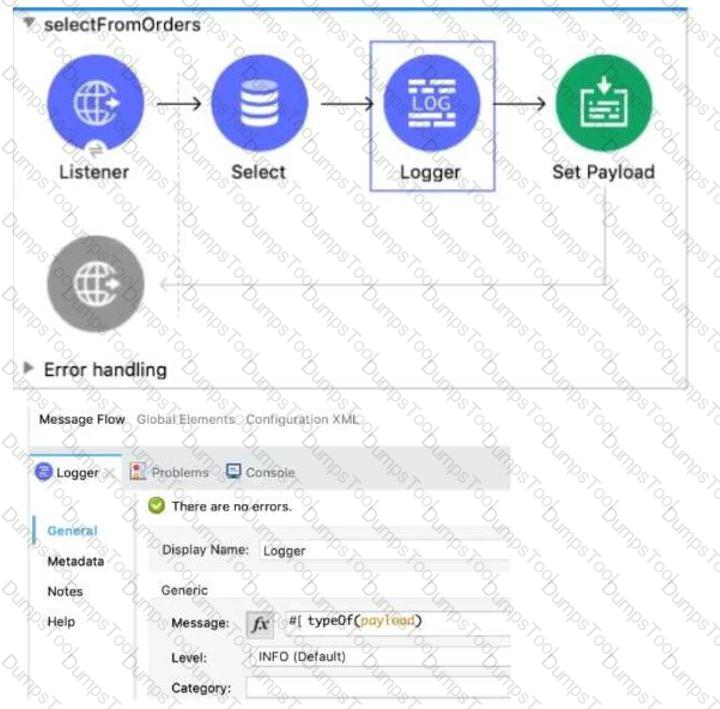
 Table
Description automatically generated
Table
Description automatically generated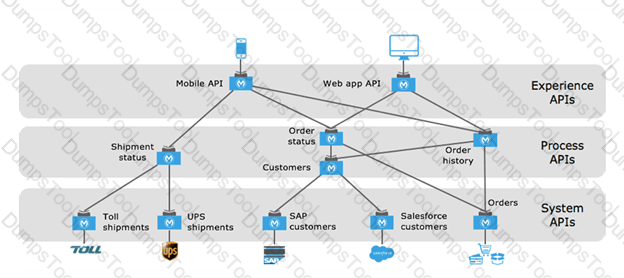 Diagram
Description automatically generated
Diagram
Description automatically generated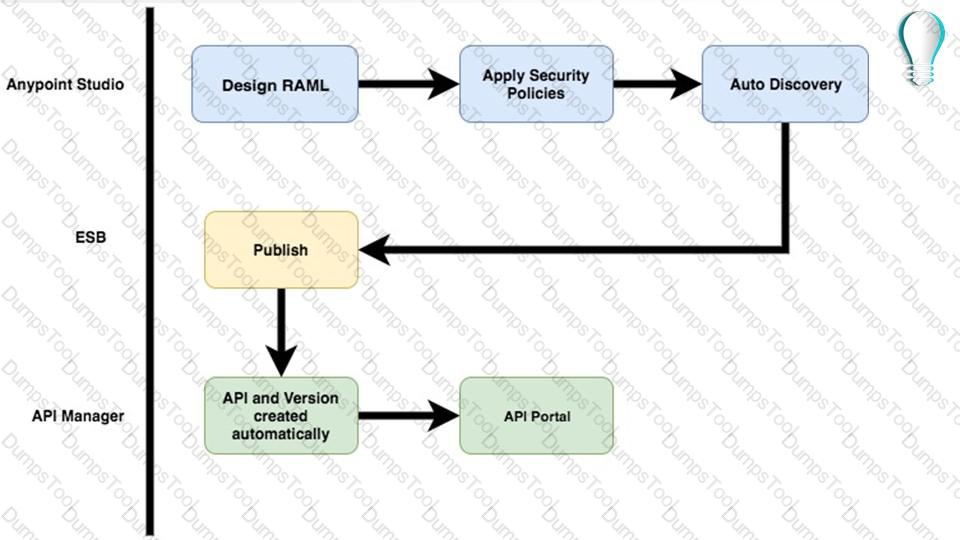 Diagram
Description automatically generated
Diagram
Description automatically generated
 Diagram
Description automatically generated
Diagram
Description automatically generated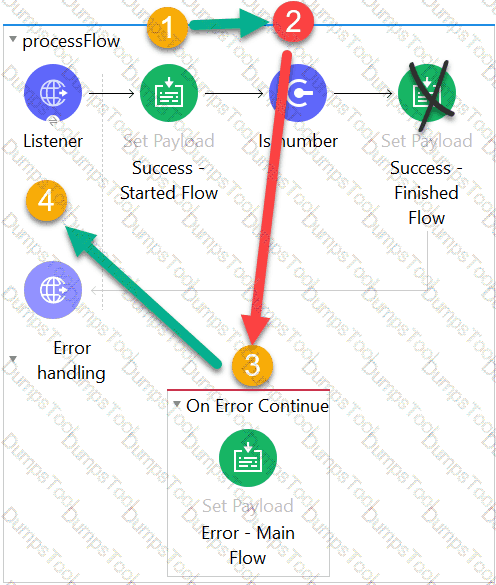 Timeline
Description automatically generated with medium confidence
Timeline
Description automatically generated with medium confidence