A data scientist is utilizing MLflow to track their machine learning experiments. After completing a series of runs for the experiment with experiment ID exp_id, the data scientist wants to programmatically work with the experiment run data in a Spark DataFrame. They have an active MLflow Client client and an active Spark session spark.
Which of the following lines of code can be used to obtain run-level results for exp_id in a Spark DataFrame?
A machine learning engineer wants to move their model versionmodel_versionfor the MLflow Model Registry modelmodelfrom the Staging stage to the Production stage using MLflow Clientclient.
Which of the following code blocks can they use to accomplish the task?
A)

B)

C)

D)

E)

A machine learning engineer and data scientist are working together to convert a batch deployment to an always-on streaming deployment. The machine learning engineer has expressed that rigorous data tests must be put in place as a part of their conversion to account for potential changes in data formats.
Which of the following describes why these types of data type tests and checks are particularly important for streaming deployments?
Which of the following is a simple statistic to monitor for categorical feature drift?
Which of the following MLflow operations can be used to delete a model from the MLflow Model Registry?
A machine learning engineer is monitoring categorical input variables for a production machine learning application. The engineer believes that missing values are becoming more prevalent in more recent data for a particular value in one of the categorical input variables.
Which of the following tools can the machine learning engineer use to assess their theory?
A machine learning engineer is in the process of implementing a concept drift monitoring solution. They are planning to use the following steps:
1. Deploy a model to production and compute predicted values
2. Obtain the observed (actual) label values
3. _____
4. Run a statistical test to determine if there are changes over time
Which of the following should be completed as Step #3?
A data scientist has computed updated feature values for all primary key values stored in the Feature Store table features. In addition, feature values for some new primary key values have also been computed. The updated feature values are stored in the DataFrame features_df. They want to replace all data in features with the newly computed data.
Which of the following code blocks can they use to perform this task using the Feature Store Client fs?
A)

B)

C)

D)

E)

A machine learning engineer needs to deliver predictions of a machine learning model in real-time. However, the feature values needed for computing the predictions are available one week before the query time.
Which of the following is a benefit of using a batch serving deployment in this scenario rather than a real-time serving deployment where predictions are computed at query time?
A data scientist has developed a scikit-learn modelsklearn_modeland they want to log the model using MLflow.
They write the following incomplete code block:

Which of the following lines of code can be used to fill in the blank so the code block can successfully complete the task?
A machine learning engineer wants to move their model versionmodel_versionfor the MLflow Model Registry modelmodelfrom the Staging stage to the Production stage using MLflow Clientclient. At the same time, they would like to archive any model versions that are already in the Production stage.
Which of the following code blocks can they use to accomplish the task?
A)

B)

C)
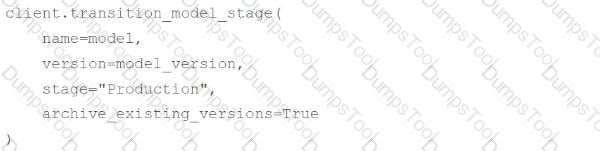
D)

A data scientist has developed a model to predict ice cream sales using the expected temperature and expected number of hours of sun in the day. However, the expected temperature is dropping beneath the range of the input variable on which the model was trained.
Which of the following types of drift is present in the above scenario?
In a continuous integration, continuous deployment (CI/CD) process for machine learning pipelines, which of the following events commonly triggers the execution of automated testing?

TESTED 02 Jun 2025