A data engineer is attempting to drop a Spark SQL table my_table and runs the following command:
DROP TABLE IF EXISTS my_table;
After running this command, the engineer notices that the data files and metadata files have been deleted from the file system.
Which of the following describes why all of these files were deleted?
A data engineering team has noticed that their Databricks SQL queries are running too slowly when they are submitted to a non-running SQL endpoint. The data engineering team wants this issue to be resolved.
Which of the following approaches can the team use to reduce the time it takes to return results in this scenario?
Which of the following describes the storage organization of a Delta table?
A data engineer wants to create a relational object by pulling data from two tables. The relational object does not need to be used by other data engineers in other sessions. In order to save on storage costs, the data engineer wants to avoid copying and storing physical data.
Which of the following relational objects should the data engineer create?
Which of the following benefits is provided by the array functions from Spark SQL?
A data engineer and data analyst are working together on a data pipeline. The data engineer is working on the raw, bronze, and silver layers of the pipeline using Python, and the data analyst is working on the gold layer of the pipeline using SQL. The raw source of the pipeline is a streaming input. They now want to migrate their pipeline to use Delta Live Tables.
Which of the following changes will need to be made to the pipeline when migrating to Delta Live Tables?
In order for Structured Streaming to reliably track the exact progress of the processing so that it can handle any kind of failure by restarting and/or reprocessing, which of the following two approaches is used by Spark to record the offset range of the data being processed in each trigger?
A data engineer has a single-task Job that runs each morning before they begin working. After identifying an upstream data issue, they need to set up another task to run a new notebook prior to the original task.
Which of the following approaches can the data engineer use to set up the new task?
Identify how the count_if function and the count where x is null can be used
Consider a table random_values with below data.
What would be the output of below query?
select count_if(col > 1) as count_a. count(*) as count_b.count(col1) as count_c from random_values col1
0
1
2
NULL -
2
3
A data engineer and data analyst are working together on a data pipeline. The data engineer is working on the raw, bronze, and silver layers of the pipeline using Python, and the data analyst is working on the gold layer of the pipeline using SQL The raw source of the pipeline is a streaming input. They now want to migrate their pipeline to use Delta Live Tables.
Which change will need to be made to the pipeline when migrating to Delta Live Tables?
A data engineer needs access to a table new_uable, but they do not have the correct permissions. They can ask the table owner for permission, but they do not know who the table owner is.
Which approach can be used to identify the owner of new_table?
Identify the impact of ON VIOLATION DROP ROW and ON VIOLATION FAIL UPDATE for a constraint violation.
A data engineer has created an ETL pipeline using Delta Live table to manage their company travel reimbursement detail, they want to ensure that the if the location details has not been provided by the employee, the pipeline needs to be terminated.
How can the scenario be implemented?
A Delta Live Table pipeline includes two datasets defined using STREAMING LIVE TABLE. Three datasets are defined against Delta Lake table sources using LIVE TABLE.
The table is configured to run in Development mode using the Continuous Pipeline Mode.
Assuming previously unprocessed data exists and all definitions are valid, what is the expected outcome after clicking Start to update the pipeline?
A data analyst has created a Delta table sales that is used by the entire data analysis team. They want help from the data engineering team to implement a series of tests toensure the data is clean. However, the data engineering team uses Python for its tests rather than SQL.
Which of the following commands could the data engineering team use to access sales in PySpark?
A data engineer needs to create a table in Databricks using data from their organization's existing SQLite database. They run the following command:
CREATE TABLE jdbc_customer360
USING
OPTIONS (
url "jdbc:sqlite:/customers.db", dbtable "customer360"
)
Which line of code fills in the above blank to successfully complete the task?
Which of the following describes a scenario in which a data engineer will want to use a single-node cluster?
A data engineer has created a new database using the following command:
CREATE DATABASE IF NOT EXISTS customer360;
In which of the following locations will the customer360 database be located?
A data engineer has been given a new record of data:
id STRING = 'a1'
rank INTEGER = 6
rating FLOAT = 9.4
Which of the following SQL commands can be used to append the new record to an existing Delta table my_table?
The Delta transaction log for the ‘students’ tables is shown using the ‘DESCRIBE HISTORY students’ command. A Data Engineer needs to query the table as it existed before the UPDATE operation listed in the log.
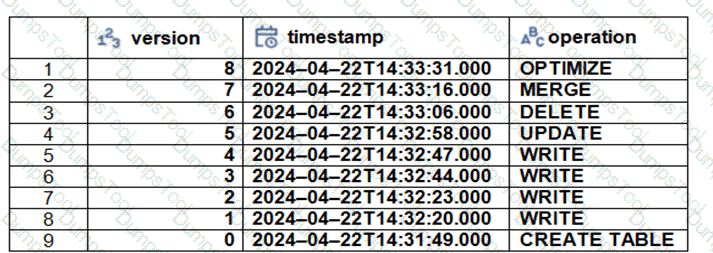
Which command should the Data Engineer use to achieve this? (Choose two.)
Which two components function in the DB platform architecture’s control plane? (Choose two.)
Which of the following commands can be used to write data into a Delta table while avoiding the writing of duplicate records?
Which of the following SQL keywords can be used to convert a table from a long format to a wide format?
In which of the following scenarios should a data engineer select a Task in the Depends On field of a new Databricks Job Task?
A data engineer has been using a Databricks SQL dashboard to monitor the cleanliness of the input data to a data analytics dashboard for a retail use case. The job has a Databricks SQL query that returns the number of store-level records where sales is equal to zero. The data engineer wants their entire team to be notified via a messaging webhook whenever this value is greater than 0.
Which of the following approaches can the data engineer use to notify their entire team via a messaging webhook whenever the number of stores with $0 in sales is greater than zero?

TESTED 30 Jun 2025