A data engineer noticed improved performance after upgrading from Spark 3.0 to Spark 3.5. The engineer found that Adaptive Query Execution (AQE) was enabled.
Which operation is AQE implementing to improve performance?
A data engineer is working on the DataFrame:
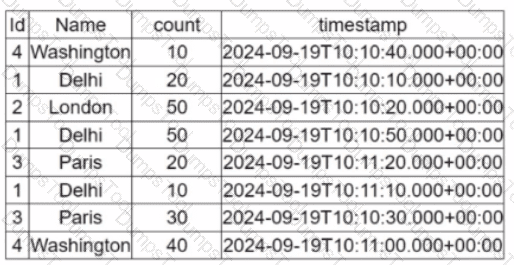
(Referring to the table image: it has columnsId,Name,count, andtimestamp.)
Which code fragment should the engineer use to extract the unique values in theNamecolumn into an alphabetically ordered list?
A Spark developer is building an app to monitor task performance. They need to track the maximum task processing time per worker node and consolidate it on the driver for analysis.
Which technique should be used?
A data scientist is working on a project that requires processing large amounts of structured data, performing SQL queries, and applying machine learning algorithms. The data scientist is considering using Apache Spark for this task.
Which combination of Apache Spark modules should the data scientist use in this scenario?
Options:
A data engineer needs to persist a file-based data source to a specific location. However, by default, Spark writes to the warehouse directory (e.g., /user/hive/warehouse). To override this, the engineer must explicitly define the file path.
Which line of code ensures the data is saved to a specific location?
Options:
A Data Analyst needs to retrieve employees with 5 or more years of tenure.
Which code snippet filters and shows the list?
A data engineer writes the following code to join two DataFramesdf1anddf2:
df1 = spark.read.csv("sales_data.csv") # ~10 GB
df2 = spark.read.csv("product_data.csv") # ~8 MB
result = df1.join(df2, df1.product_id == df2.product_id)

Which join strategy will Spark use?
A developer wants to test Spark Connect with an existing Spark application.
What are the two alternative ways the developer can start a local Spark Connect server without changing their existing application code? (Choose 2 answers)
How can a Spark developer ensure optimal resource utilization when running Spark jobs in Local Mode for testing?
Options:
A developer notices that all the post-shuffle partitions in a dataset are smaller than the value set forspark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold.
Which type of join will Adaptive Query Execution (AQE) choose in this case?
An MLOps engineer is building a Pandas UDF that applies a language model that translates English strings into Spanish. The initial code is loading the model on every call to the UDF, which is hurting the performance of the data pipeline.
The initial code is:

def in_spanish_inner(df: pd.Series) -> pd.Series:
model = get_translation_model(target_lang='es')
return df.apply(model)
in_spanish = sf.pandas_udf(in_spanish_inner, StringType())
How can the MLOps engineer change this code to reduce how many times the language model is loaded?
A data scientist at a financial services company is working with a Spark DataFrame containing transaction records. The DataFrame has millions of rows and includes columns fortransaction_id,account_number,transaction_amount, andtimestamp. Due to an issue with the source system, some transactions were accidentally recorded multiple times with identical information across all fields. The data scientist needs to remove rows with duplicates across all fields to ensure accurate financial reporting.
Which approach should the data scientist use to deduplicate the orders using PySpark?
Which Spark configuration controls the number of tasks that can run in parallel on the executor?
Options:
Given a CSV file with the content:

And the following code:
from pyspark.sql.types import *
schema = StructType([
StructField("name", StringType()),
StructField("age", IntegerType())
])
spark.read.schema(schema).csv(path).collect()
What is the resulting output?
A data engineer wants to process a streaming DataFrame that receives sensor readings every second with columnssensor_id,temperature, andtimestamp. The engineer needs to calculate the average temperature for each sensor over the last 5 minutes while the data is streaming.
Which code implementation achieves the requirement?
Options from the images provided:
A)
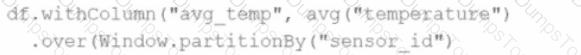
B)

C)

D)

A data engineer is working on a real-time analytics pipeline using Apache Spark Structured Streaming. The engineer wants to process incoming data and ensure that triggers control when the query is executed. The system needs to process data in micro-batches with a fixed interval of 5 seconds.
Which code snippet the data engineer could use to fulfil this requirement?
A)

B)

C)

D)

Options:
A developer needs to produce a Python dictionary using data stored in a small Parquet table, which looks like this:

The resulting Python dictionary must contain a mapping of region-> region id containing the smallest 3 region_idvalues.
Which code fragment meets the requirements?
A)

B)

C)

D)

The resulting Python dictionary must contain a mapping ofregion -> region_idfor the smallest 3region_idvalues.
Which code fragment meets the requirements?
A data analyst wants to add a column date derived from a timestamp column.
Options:
A data scientist is working on a large dataset in Apache Spark using PySpark. The data scientist has a DataFramedfwith columnsuser_id,product_id, andpurchase_amountand needs to perform some operations on this data efficiently.
Which sequence of operations results in transformations that require a shuffle followed by transformations that do not?
Which feature of Spark Connect is considered when designing an application to enable remote interaction with the Spark cluster?

TESTED 01 Jun 2025