A security analyst notices that regardless of user-submitted prompts, an AI model always returns unsanitized responses. These responses are then passed to multiple plug-ins. The analyst is concerned with the potential security implications.
Which of the following Open Worldwide Application Security Project (OWASP) categories addresses this vulnerability?
A security analyst needs to conduct a security assessment of the output from an AI-enabled development tool.
Which of the following should the analyst do first?
A SOC team has an AI agent that performs web searches and calls to the SOAR solution. The team is concerned about enterprise uptime and case resolution time.
Which of the following is the most appropriate use of the AI agent?
A security alert triggers an agentic system. An analyst notices the following payload in the logs. The alert includes multiple shell commands that are not typically run as part of any hardening:

Which of the following is the most effective control to implement?
Which of the following is the primary security risk when deploying AI models in production?
A human resources officer is using AI to evaluate resumes and help select candidates that meet minimum criteria. To improve the results, the human resources officer adjusts the query parameters and includes an example resume that matches a successful candidate.
Which of the following best describes this query?
A short AI-generated video shows a celebrity ' s likeness talking about a fake public security event.
Which of the following was used to create this video?
A company deploys an internet-facing chatbot using RAG. Logs show that an administrator can retrieve employee names and usernames while an employee receives ' information not available. ' Which of the following is reducing the risk of sensitive data exposure in this scenario?
Customer feedback for an AI chatbot has a high-rate of non-answers, which is causing higher central processing unit (CPU) utilization.
Which of the following should be implemented?
A security administrator sees suspicious queries on AI logs.
Which of the following should the administrator implement to address this issue?
A security administrator wants to prevent prompt injection attacks and ensure responses have sanitized output.
Which of the following provides a primary compensating control for these requirements?
An airline corporation wants to implement a chatbot application using a large language model (LLM) so its customers can ask questions and receive answers about flight details and have the option to upload files.
Which of the following security controls should the airline use to protect against malicious input and unauthorized use beyond the service-level agreement? (Choose two.)
A line of business wants to onboard an application that uses a custom AI model for employee assessments. The Chief Information Officer (CIO) agrees to allow the engagement to proceed but first wants a threat model.
Which of the following is the most appropriate to use for an AI threat model?
A company uses human review for software development validation and wants to add another validation layer.
Which of the following should a security administrator use to accomplish this task?
A cybersecurity administrator needs a security mechanism that can validate input.
Which of the following controls should the administrator use?
Which of the following is the most impactful security risk associated with the use of a generative AI chatbot?
A security analyst is preparing a presentation for the sales team that describes the most common vulnerabilities that are specific to AI applications.
Which of the following is the best source for the analyst to consult?
User experience is declining since the launch of a large language model (LLM) in internal networks.
Which of the following should be the highest priority for the prompt engineers?
A cybersecurity analyst must use pattern recognition on a data set containing unstructured data.
Which of the following models is the best for this task?
A cybersecurity analyst wants to choose a machine learning (ML) model to classify log entries while providing the best explainability.
Which of the following models should the analyst use?
A large number of employees receive a video message in which the company ' s CEO states that the company will be filing for bankruptcy. After an investigation, it was discovered that the CEO did not send this message.
Which of the following is this scenario an example of?
A disgruntled employee changed the company policies that a chatbot references in order to create confusion and disrupt the business.
Which of the following AI-generated vulnerabilities is the employee exploiting?
Which of the following is used to train an AI model with unstructured data?
As a compliance requirement, a large language model (LLM) application requires setting up guardrails.
Which of the following resources is most appropriate to use?
Which of the following roles best supports the implementation of AI governance, risk, and compliance (GRC)? (Choose two.)
Which of the following helps end users within an organization the most in safeguarding against the risk of AI-related non-compliance?
A security architect performs threat modeling of an AI system. The architect needs to determine which attacks can be performed against the system.
Which of the following actions should the architect take next?
A management team is concerned about an unexpected cost increase for a public-facing AI chatbot.
Which of the following should a security administrator examine first to determine the root cause?
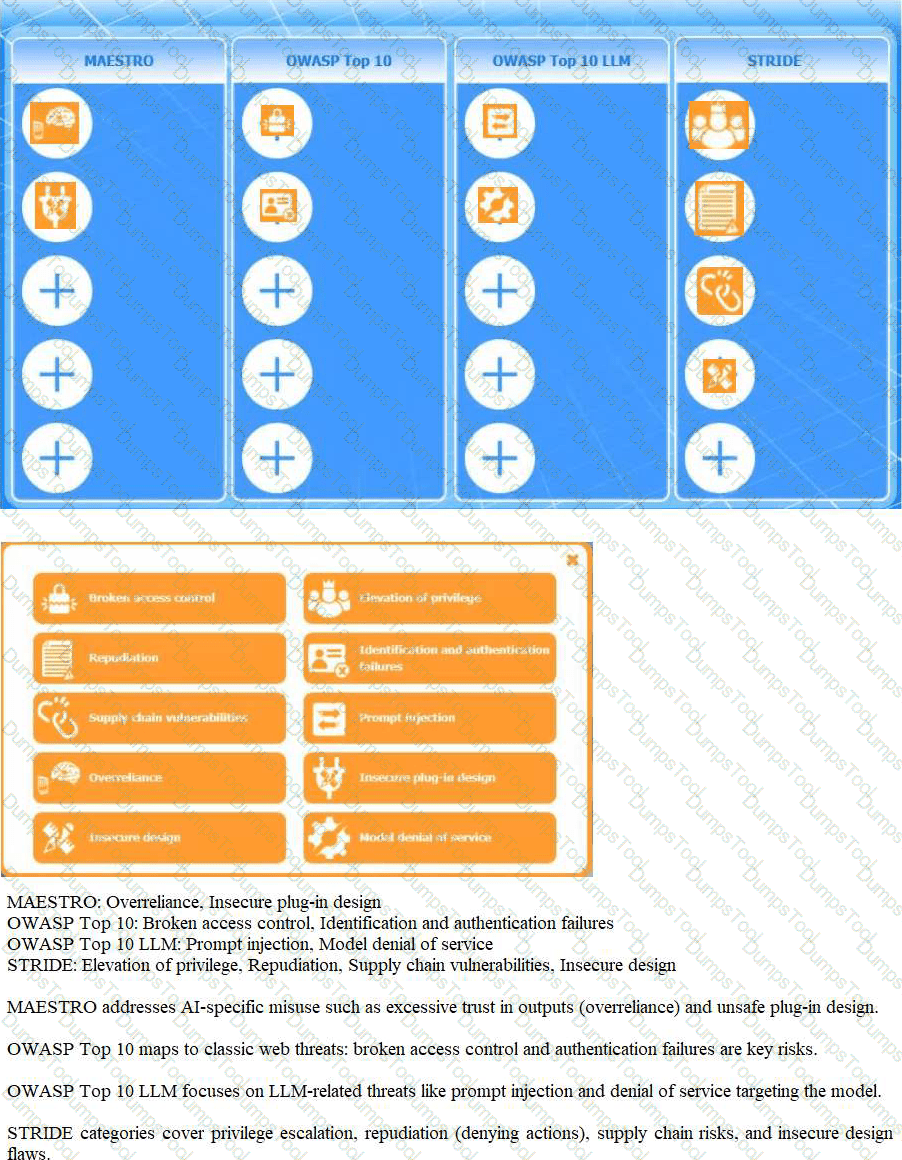
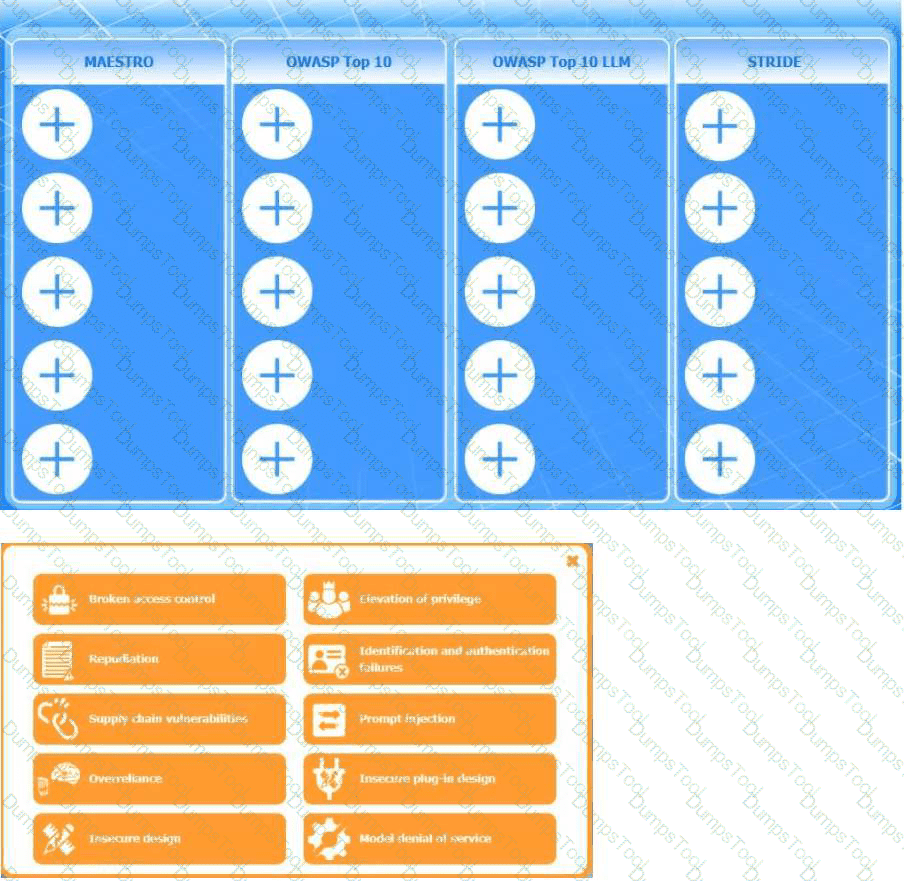
Instructions: Click the (+) to assign each threat category into its appropriate framework.
An architect is modeling an agentic system to meet security standards.
A company is adopting AI and wants to create policies and procedures that include a structure for evaluating, publishing, and approving patterns for AI usage.
Which of the following should the company establish to meet this goal?
Which of the following is required first in order to send a prompt query and response in a language model (LLM) system when authentication is enabled?

TESTED 14 Jul 2026